자연어 처리2017
트랜스포머 — Attention Is All You Need
바스와니 등이 셀프 어텐션 기반의 새로운 아키텍처를 발표
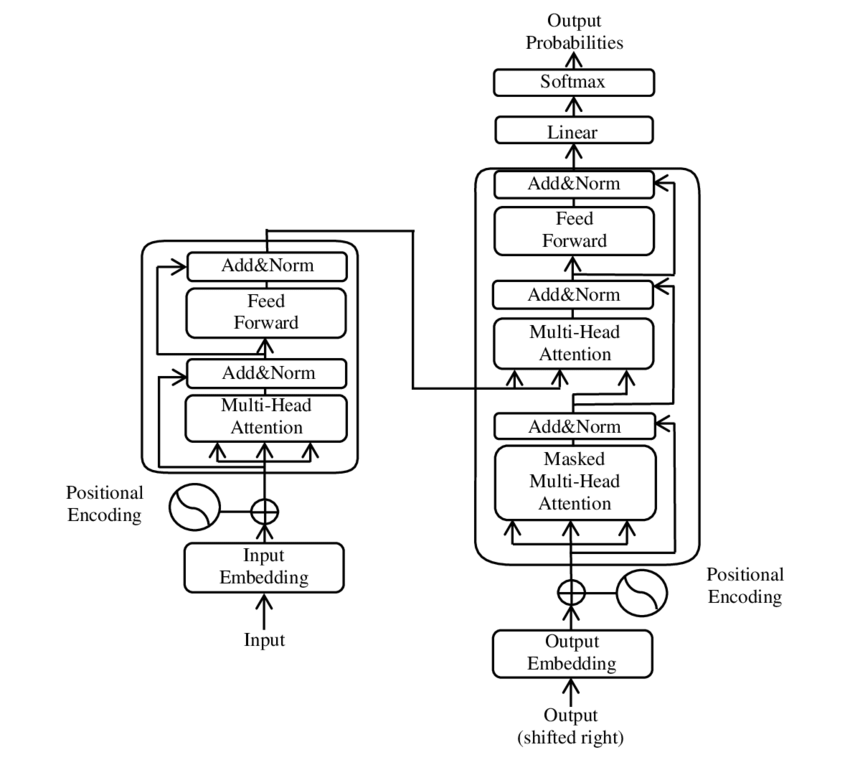
Transformer 아키텍처: 'Attention Is All You Need' 논문의 인코더-디코더 구조 (Wikimedia Commons)
트랜스포머는 RNN 없이 셀프 어텐션만으로 시퀀스를 처리합니다. 각 토큰이 다른 모든 토큰과의 관계를 동시에 계산하여 병렬 처리가 가능하고, 장거리 의존성을 잘 포착합니다.
핵심 수식
스케일드 닷-프로덕트 어텐션
Q=Query — '내가 찾고 싶은 것' (질문)
K=Key — '나는 이런 정보를 갖고 있다' (라벨)
V=Value — '실제 정보 내용' (답변)
QKᵀ=Query와 Key의 내적 — 관련도 점수 계산
√dₖ=스케일링 — 차원이 클수록 내적 값이 커지므로 나눠서 안정화
softmax=점수를 확률 분포로 변환 (합 = 1)
포지셔널 인코딩
10000=주파수 스케일 — 차원마다 다른 주기를 만들어 위치 구분
pos=토큰의 위치 (0, 1, 2, ...)
i=임베딩 차원의 인덱스
d=임베딩 전체 차원 수
sin=주기 함수 — 위치마다 고유한 패턴을 생성
핵심 개념
셀프 어텐션
시퀀스 내 모든 토큰 쌍의 관련도를 동시에 계산하는 메커니즘
멀티헤드 어텐션
여러 개의 어텐션을 병렬로 수행하여 다양한 관계를 포착
포지셔널 인코딩
순서 정보가 없는 어텐션에 위치 정보를 주입하는 기법
주요 인물
아
아쉬쉬 바스와니
Transformer 논문 1저자 (Google Brain)
노
노암 샤지어(Noam Shazeer)
논문 시니어 저자, MoE 등 후속 연구
영향 & 의의
현대 AI의 근간. GPT, BERT, T5 등 거의 모든 대형 모델이 트랜스포머 기반이며, NLP를 넘어 비전(ViT), 오디오, 코드까지 확장되었습니다.
용어집
TransformerTransformer
어텐션만으로 시퀀스를 처리하는 아키텍처. RNN 없이 병렬 처리 가능. GPT/BERT의 기반
Q, K, VQuery, Key, Value
어텐션의 3요소. Q로 검색하고, K로 매칭하고, V에서 정보를 가져오는 구조
Self-AttentionSelf-Attention (자기 어텐션)
시퀀스 내 모든 토큰이 서로의 관련도를 동시에 계산하는 메커니즘
Multi-HeadMulti-Head Attention
여러 개의 어텐션을 병렬 수행. 각 헤드가 다른 관계 패턴을 포착
PEPositional Encoding
위치 인코딩. 어텐션에는 순서 개념이 없으므로 sin/cos 함수로 위치 정보를 주입
softmaxSoftmax Function
실수 벡터를 확률 분포(합=1)로 변환. 어텐션 가중치를 정규화하는 데 사용